

Le renseignement de menaces se concentre sur l’organisation, l’analyse et le développement d’informations pointilleuses visant à protéger et prévenir une organisation (gouvernementale ou privée) contre une cyber-attaque (Tounsi et Rais, 2018). Le cycle de vie de cette discipline implique généralement 6 phases : la direction, la collection, le traitement, l’analyse, la dissémination et le retour (voir Fig. 1). Les sources d’informations peuvent prévenir du clearweb ou du darkweb. Toutes sources d’informations publiques et ouvertes (open-source) sont pertinentes afin de prévenir les attaques ou d’informer une organisation face à un vol de données déjà complété. Étant une discipline récente, la littérature à son sujet est très récente et gagnerait à être plus développée.
Les chercheurs Cascavilla, Tamburri et Van Den Heuvel (2021) ont réalisé une revue systématique regroupant des articles et rapports provenant de la littérature grise et blanche. Les chercheurs visent notamment à répondre à cinq questions de recherche : 1) Quels niveaux de profondeur en ligne sont évalués et dans quelle mesure? 2) Quels degrés d’anonymat dans la recherche web est-il possible d’obtenir? 3) Quelles politiques existent pour faire varier les degrés d’anonymat? 4) Quelles fonctionnalités d’un site web sont les plus indicatives de cybermenaces? 5) Quelles techniques d’évaluation des risques existent à ce jour?
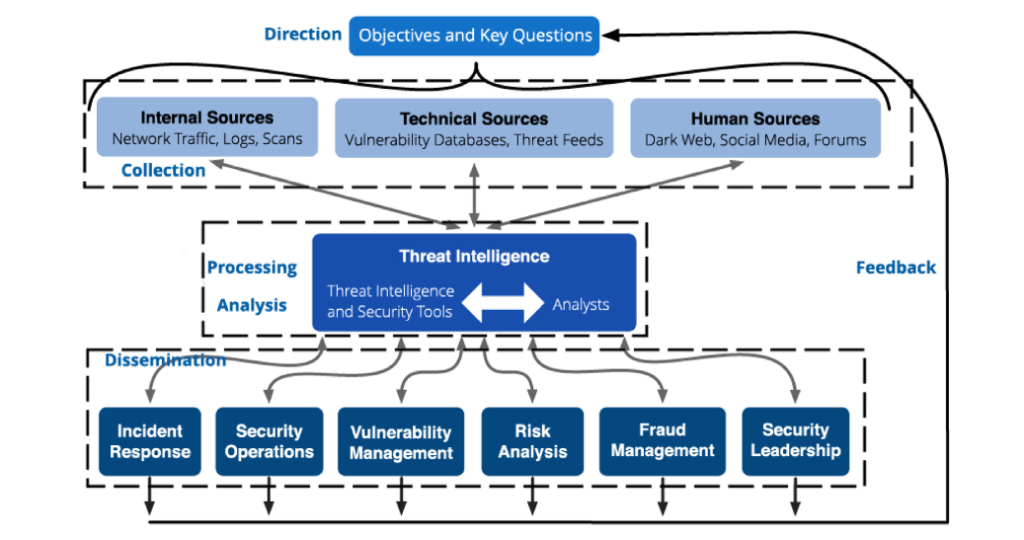
Figure 1. Cycle de vie du renseignement de menaces
Afin de sélectionner des articles pertinents, les auteurs ont utilisé divers critères d’inclusion et d’exclusion pour. 374 études furent choisies à la suite du processus d’inclusion/exclusion.
Les chercheurs ont trouvé les principales conclusions suivantes provenant de leurs questions de recherche :
1) Quels niveaux de profondeur en ligne sont évalués et dans quelle mesure?
L’ingénierie et la gestion des cybermenaces en profondeur et sur le darkweb reposent en grande partie sur l’analyse basée sur le réseau ainsi que sur l’exploration d’artefacts de bas niveau (par exemple, l’exploration de paquets, l’analyse de code, etc.). Plus de données d’ordre supérieur et multi-vocales restent inutilisées et méritent une plus grande attention.
2) Quels degrés d’anonymat dans la recherche web est-il possible d’obtenir?
Il n’existe aucune procédure d’anonymat d’exploration/analyse concluante; cette voie est ouverte à d’autres opportunités de recherche et a un besoin urgent d’être abordée par les principales agences d’application de la loi à travers l’Union européenne.
3) Quelles fonctionnalités du site Web sont les plus indicatives de cybermenaces?
Surface, la littérature d’analyse Web, prédit les caractéristiques du code logiciel par rapport aux métriques d’apparence pour l’évaluation des risques des sources en ligne ; à l’inverse, la littérature sur l’analyse du Web profond et sombre semble être de prédilection pour les caractéristiques d’apparence, par exemple, l’exploration de contenu de texte de site Web.
4) Quelles techniques d’évaluation des risques existent à ce jour?
Ce qui se trouve en surface. La littérature d’analyse Web s’est révélée principalement affectée par les attaques de logiciels malveillants et l’exploitation des vulnérabilités des logiciels et du système d’exploitation.
Cette étude permet de répondre à plusieurs questions fondamentales de la discipline du renseignement de menaces. Les auteurs ouvrent la discussion sur la pertinence d’encourager les praticiens et les chercheurs à se concentrer sur la création d’un outil holistique visant à aider les forces de l’ordre dans la lutte contre les cyber criminels, à favoriser la création d’une communauté ouverte face au partage de connaissances entre les analystes et à créer des outils qui visent l’évaluation des risques liés aux activités criminelles pour des bases de données massives.
Pour citer l’article: Cascavilla, G., Tamburri, D., Van Den Heuvel, W. (2021). Cybercrime theat intelligence: A systematic multi-vocal literature review. Computers & Security, 105. https://doi.org/10.1016/j.cose.2021.102258

